When searching in a text field (see Find/Select Dialog) there are over two dozen options for determining whether data is a match.
Contains — Any data cell that contains the match value will be identified as a match. For example, if you ask Panorama to locate cities containing an, it will locate cities like Anaheim, Lansing, Los Angeles, and San Jose since they all contain an. Notice that capitalization is ignored, so an, An, AN, and aN are all acceptable matches.
Does Not Contain — Any data cell that does not contain the match value will be identified as a match. For example, if you ask Panorama to locate phone numbers not containing (714) it will locate phone numbers in other area codes. Capitalization is ignored, so an, An, AN, and aN are all equivalent as far as this option is concerned.
Begins With — Any data cell that begins with the match value will be identified as a match. For example, if you ask Panorama to locate states beginning with co, it will locate states like Colorado and Connecticut. Capitalization is ignored, so (co*, Co, CO, and cO are all acceptable matches.
Ends With — Any data cell that ends with the match value will be identified as a match. For example, if you ask Panorama to locate baseball teams ending with sox it will locate both Red Sox and White Sox. Capitalization is ignored, so sox, Sox, SOX, and sOx are all acceptable matches.
Is Equal to (=) — Any data cell that exactly matches the match value will be identified as a match. An exact match means just that. The spelling, punctuation, and capitalization must be exactly the same -— for example red will not match RED or Red.
Is Not Equal to (≠) — Any data cell that does not exactly match the match value will be identified as a match.
Is Less Than (<) — Any data cell that is less than the value in the box on the right will be identified as a match.
Is Greater Than (>) — Any data cell that is greater than the match value will be identified as a match.
Is Less Than or Equal to (≤) — Any data cell that is less than or equal to the match value will be identified as a match.
Is Greater Than or Equal to (≥) — Any data cell that is greater than or equal to the match value will be identified as a match.
Is Between — This option combines Is Greater Than or Equal To and Is Less Than or Equal To into a single line.
Is Not Between — This option combines Is Less Than and Is Greater Than into a single line.
Is Empty — This option matches if the specified field is empty (does not contain any value).
Is Not Empty — This option matches if the specified field is not empty (does contain a value).
Contains the Word — Any data cell that contains the specified word will be identified as a match. The word must not be part of a larger word. For example, if you specify contains the word engineer it will not match engineers or engineering.
Sounds Like — Any data cell that “sounds like” the match value will be identified as a match. Panorama uses a special algorithm to determine which values sound like the match value. This algorithm is not perfect, but it does work pretty well. For example, if you are looking for someone named Luboviski but you are not sure if it is spelled with an i, ie, or y, the sounds like match will save the day. The sounds like match can be used with more than one word at a time. For example, if you are searching through a video rental database for the movie Escape from New York, the sounds like algorithm will find it even if it is misspelled Escapade from New York. If any word in the match value sounds like any word in the data cell, the data will be identified as a match.
Note: If two words do not start with the same letter, the sounds like algorithm will not think they sound alike. For example, sounds like does not think that Chris and Kris sound alike.
Matches (Wildcard) — This option allows you to create a “pattern” for comparing data. The pattern allows you to set up very flexible “wildcard” matches where some characters must match but others don’t have to. The pattern must contain one or more “normal” characters (letters, numbers, punctuation, etc.) and also may contain one or more of the wildcard characters ? (question mark) and * (asterisk). The ? wildcard character will match any character in this position. The * wildcard character will match any number of characters in this position.
A few examples should help to make the operation of the wildcard characters within the pattern clear. Suppose you want to find all records where the first three digits of the zip code are 926, and you don’t care what the last three digits are. The pattern will be 926??. This pattern will match any five digit zip code that begins with 926. It will not match if there are less than or more than 5 characters in the zip code.
If the pattern is changed to 926*, Panorama will match with any zip code that begins with 926, no matter what the length is. It could be three digits long or thirty — Panorama doesn’t care and will say that it matches as long as it starts with 926.
By changing the pattern to 926??* we tell Panorama to match any zip code that starts with 926 and is at least five characters long. The zip code could be 5, 6, 7, or 70 characters long, but will not match if it is only 3 or 4 characters long.
If you wanted to select only 9 digit zip codes you could use the pattern ?????-????. This will match any 10 character long string with a - (dash) in the sixth position.
Suppose that you wanted to find everyone in your database with the last name Johnson and the first initial J. Assuming that the first and last names are stored in a single field, you could use the pattern j*johnson to locate the person (or persons) you are looking for. The match option doesn’t care about upper or lower case, so this pattern would match Jerry Johnson, jim johnson, or JOHN JOHNSON. (It will also match weird data like j346ujohnson or j@#opcjohnson, so take care to watch for unexpected matches – you can use a regular expression match for more specificity.) If you want upper and lower case treated as different characters use the matches exact case option (see below).
Matches Exact Case — This option is the same as the Matches (wildcard) option (see above), except that any letters in the data must exactly match the pattern, including upper vs. lower case. For example, if the pattern is J*Johnson, names like Jerry Johnson will match, but JERRY JOHNSON will not match.
Matches Regular Expression — A regular expression (sometimes abbreviated to regex) is a way for a computer user or programmer to express how a computer program should look for a specified pattern in text and then what the program is to do when each pattern match is found. Regular expressions can be designed to perform complex searches for just about anything – email addresses, phone numbers, urls, prices, part numbers, you name it. In fact, entire books have been written about regular expressions and how to use them. See Regular Expressions for more detailed information.
Here is a simple example that illustrates regular expressions in action. This example searches the Address field looking for instances where a numeric digit ([0-9]) is followed by an upper case alphabetic character ([A-Z]). It turns out that about 4% of the addresses in this database have this combination, the blue arrows show some of them.
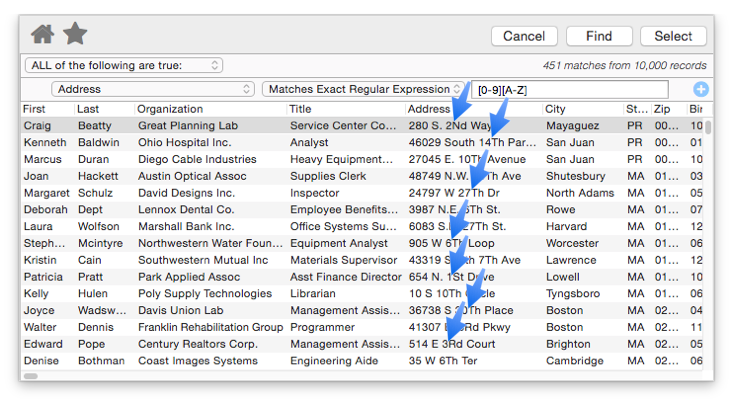
Matches Exact Regular Expression — This option is the same as the Matches Regular Expression option (see above), except that any matches involving letters must be exact, including upper vs. lower case. The example in the previous section actually uses this option, otherwise it would have found numeric digits followed by any alphabetic character, whether upper or lower case.
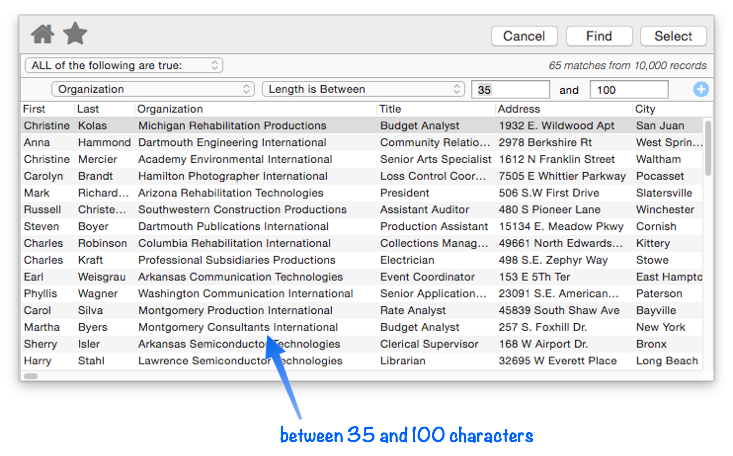
Length is Between — When this option is selected there are two match values, the minimum and maximum length (in characters). In this example this option is being used to search for organizations with unusually long names (is equal to or more than 35 characters).
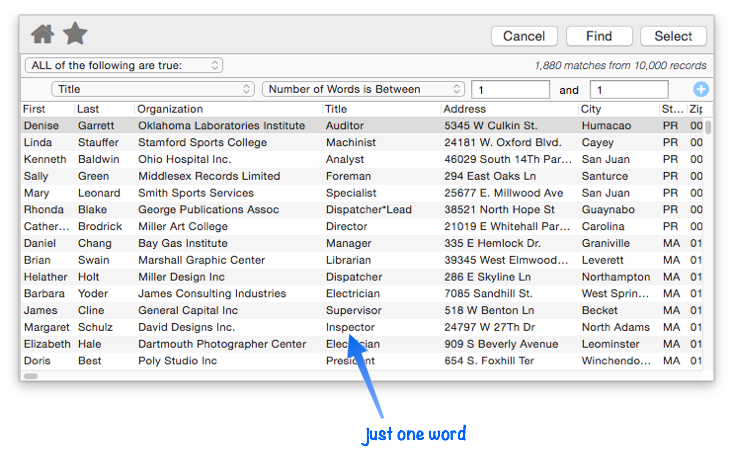
Number of Words is Between — When this option is selected there are two match values, the minimum and maximum number of words. In this example this option is being used to search for job titles with only one word in them (excluding compound titles like vice president or security analyst).
Number of Lines is Between — When this option is selected there are two match values, the minimum and maximum number of lines. For example, you could use this to find all records where a cell contained more than one line by using 2 for the minimum number of lines and 9999 for the maximum.
Is All Upper Case — Any data cell that contains all upper case characters (for example AZ) will be identified as a match.
Is All Lower Case — Any data cell that contains all lower case characters (for example west) will be identified as a match.
Is All Word Caps — Any data cell that contains words with the first character captialized (for example San Diego) will be identified as a match.
Is Not All Upper Case — Any data cell that contains any lower case characters (for example az) will be identified as a match. This is useful for double checking that a column is all upper case (for example a column of state abbreviations).
Is Not All Lower Case — Any data cell that contains any upper case characters (for example West) will be identified as a match.
Is Not Word Caps — Any data cell that contains words with the first character lower case, or any other character upper case (for example hOusTon, CHICAGO or philadelphia) will be identified as a match. This is useful for double checking the capitalization of fields containing proper names.
See Also
- checkemptyselection -- notifies the user if a selection failed, and reverts to the previous selection.
- Date Search Options -- searching dates within a database.
- Favorite Searches -- saving and recalling favorite searches.
- find -- locates the first visible record in the active database for which the specified condition is true.
- Find & Replace Dialog -- finding and replacing a word or phrase (with an option to use a regular expression).
- Find/Select Dialog -- using a dialog to search for specific data.
- findabove -- locates the next previous record (above the current record) in the active database for which the specified condition is true.
- findbackwards -- locates the last visible record in the active database for which the specified condition is true.
- findbelow -- locates the next visible record (below the current record) in the active database for which the specified condition is true.
- findid -- locates a record in the active database by its ID number (see info("serverrecordid").
- findnth -- finds the nth (2nd, 3rd, 4th, etc.) record that matches a true-false test.
- findselect -- opens the standard *Find/Select* dialog.
- findselectdialog -- opens the standard *Find/Select* dialog.
- Formula Search -- searching with a formula.
- Handling Empty Selections in Code -- dealing with an empty selection data set.
- ifselect -- combines the select and if info("empty") operations into a single statement.
- info("empty") -- returns true or false depending on the result of the last select operation. If no records were selected the function will return true, otherwise it will return false.
- info("found") -- returns true or false depending on whether the last *find* or *next* statement was successful.
- info("selectduplicatesortwarning") -- works with the selectduplicatesnowarning statement to ascertain whether or not the database was sorted correctly when last search for duplicates was performed.
- nextmatch -- locates the next visible record in the active database for which the condition specified in the most recent Find statement is true.
- Numeric Search Options -- searching numbers within a database.
- pleaseselectall -- makes sure that all records are selected.
- previousmatch -- locates the previous (closer to the top) visible record in the active database for which the condition specified in the most recent Find statement is true.
- Record Search Options -- searching via record attributes.
- Refining a Selection -- selecting a subset or superset of a previous selection."
- removeselected -- deletes all selected records from the database.
- removeunselected -- deletes all unselected records from the database.
- safeselect -- makes visible only those records for the active database for which the specified condition is true. If no records match, the previous selection is retained.
- safeselectwithin -- makes visible only those previously selected records in the active database for which the specified condition is true. If no records match, the previous selection is retained.
- search( -- searches through an item of text looking for a character, word or phrase. If it finds an exact match (including upper/lower case) with the character, word or phrase, it returns its position within the text item. If it does not find the character, word or phrase, it returns zero.
- searchanycase( -- searches through an item of text looking for a character, word or phrase. If it finds a match (upper/lower case may be different) with the character, word or phrase, it returns its position within the text item. If it does not find the character, word or phrase, it returns zero.
- Searching -- searching a database to find or select information.
- select -- makes visible only those records for the active database for which the specified condition is true.
- Select Duplicates Dialog -- opens the standard *Select Duplicates* dialog sheet.
- selectadditional -- adds unselected records to a previously selected group if they match the true-false test.
- selectall -- makes every record in the database visible.
- selectduplicates -- selects records containing duplicate information in the database.
- selectduplicatesnowarning -- selects records containing duplicate information in the database.
- Selecting with the Context Menu -- searching for information related to the current cell.
- selectreverse -- makes every visible record invisible, and every invisible record visible.
- selectwithin -- uses a Boolean formula to exclude records from a previously selected group.
History
| Version | Status | Notes |
| 10.0 | Updated | Carried over from Panorama 6.0, but with new options including regular expressions. |