The joinonerecord statement joins matching data from another database into the current record.
Parameters
This statement has one parameter:sourcedatabase – is the name of the database to be joined with the current database. This database must be open. (Note: See the text below for alternative uses of this parameter, as well as the option of multiple parameters.
Description
This statement joins data from another database (called the Source Database) into the current record. (This is similar to the join statement, but joinonerecord only works with the current record, not the entire current database.) The source database must be open before the join statement is used (see opendatabase and Auxiliary Databases). The data is joined by matching a key in the current database with a key in the source database. The keys can be fields, or can be a more complicated formula. These keys define the relationship between the two databases (this operation is sometimes called a relational join).
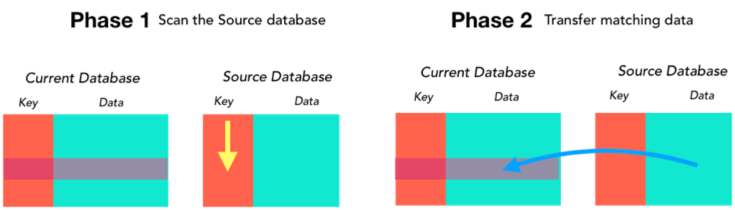
The joinonerecord statement first scans the source database to locate a record that matches the current record, then copies one or more fields from the matching record into the current record.
Performing a One Record Join using a Relation Template
The easiest way to use the joinonerecord statement is to set up a relational template in advance with the File>Database Options>Relations panel. Here’s an overview of this panel.
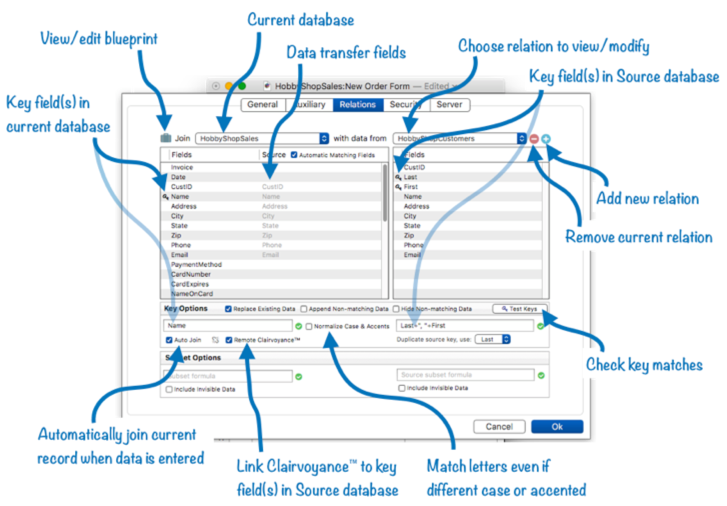
See Relational Database Management to learn all the details of using this panel.
If you’ve set up and saved a relation using this panel, you can use the joinonerecord statement with only one parameter – the name of the database. This code will join the current record in the current database with the corresponding record in the HobbyShopCustomers database using the key fields and other options specified in the File>Database Options>Relations panel.
joinonerecord "HobbyShopCustomers"
Sometimes the pre-saved template is almost what you want, but not quite. In that case, you can append the options described below to this statement to “tweak” how joinonerecord works. This example performs the same join as before, but only on the subset of records in California in both databases (the subset option is described in more detail further down on this page.)
joinonerecord "HobbyShopCustomers",
"source subset",{State="CA"}
The extra options can also be specified in a dictionary, like this:
let extraJoinOptions = initializedictionary("source subset",{State="CA"})
joinonerecord "HobbyShopCustomers",extraJoinOptions
Auto Join
The most common need for performing a one record join is during data entry. When a key value is enterd, joinonerecord can be used to retrieve additional information and automatically enter it into the current record. In fact, this need is so common that it is built into Panorama itself. So in most cases, you don’t need to actually write any code that uses the joinonerecord statement, you can simply check the Auto Join checkbox in the Database Options>Relation panel (see Relational Database Management to learn more about this panel).
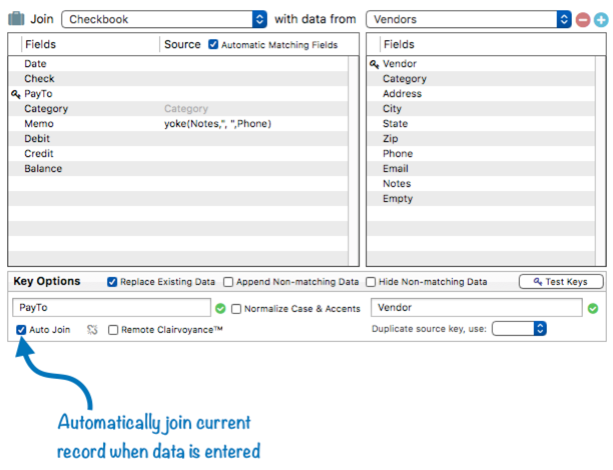
Whenever a key value is entered, Panorama automatically invokes the joinonerecord statement for you, and populates the fields specified by the relation template with the data that belongs to the match.
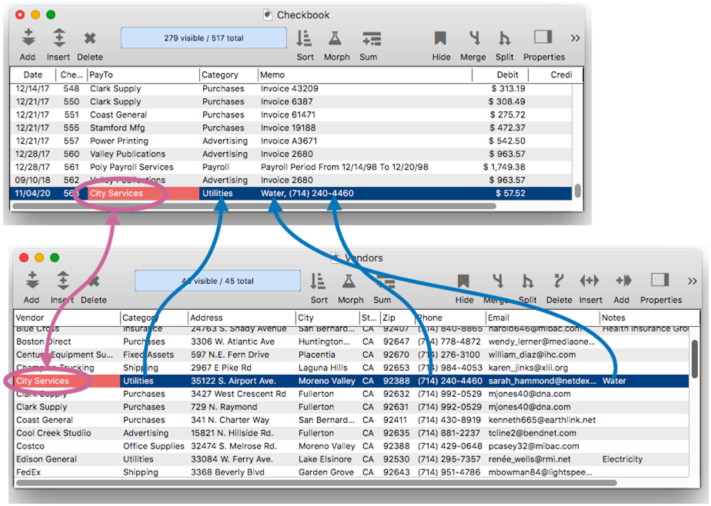
What if I need even more customization? – The Auto Join feature is very flexible, but if it doesn’t do what you want, you can leave this checkbox off and manually code the join action to take when doing data entry. See Automatic Field Code to learn how to write code that is performed after data entry, and joinonerecord to learn how the join code is written. This illustration shows how this is done (though this example is silly, because the same results could be achieved simply by checking the Auto Join checkbox.)
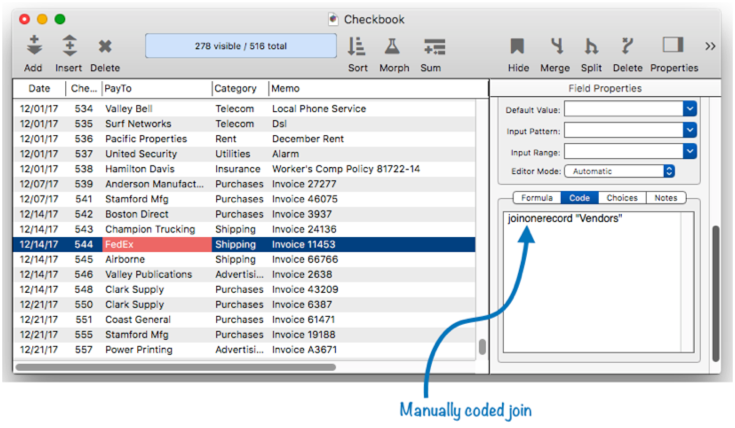
If you do manually code the join, be sure to leave the Auto Join option turned off, otherwise the join will be performed twice.
The rest of this page describes all of the options that are available to configure a joinonerecord operation. Remember, these options can be configured in the File>Database Options>Relations panel (as described in Relational Database Management), or they can be included as an explicit parameter in the joinonerecord statement itself. For clairity, all of the examples below will explicity include the parameters directly in the join statement.
JoinOneRecord Options
Joining two databases is a complicated operation. At a minimum, you must specify these basic criteria:
- What is the source database?
- What are the keys in both databases?
- What information will be transferred and into what fields?
You can also specify additional options such as how to handle missing or duplicate key values (more on this later), and you can restrict the search for a matching record to only a subset of the data in the source database.
Each joinonerecord option is specified as a name,value pair, for example "Database","Vendors" or "Key","OrderID". You can specify these options as a list of parameters, like this:
joinonerecord "database","Vendors","key","OrderID"
or you can combine all of the options into a dictionary, as shown here.
joinonerecord initializedictionary(
"database","Vendors",
"key","OrderID")
At first glance, using a dictionary may seem more complicated, and it is, but it has the advantage that you can prepare the dictionary in advance in a variable, and potentially reuse it in multiple locations in your code (including with the join statement).
Whichever method you use, the option names are case insensitive and ignore spaces, so all three of these three lines will work exactly the same.
"source key","VendorID"
"Source Key","VendorID"
"SOURCEKEY","VendorID"
If you want to temporarily disable an option, you can “comment it out” by prefixing it with two / characters, like this:
"// source key","VendorID"
This is especially useful when you have multiple options specified on a single line.
Source Database
To specify the database that will be joined into the current database, use the Database option, as shown in the examples above. The specified source database must already be open (see opendatabase and Auxiliary Databases).
The Database option is not required. If it is omitted, the current database will also be used as the source database (note that this is different than the join statement, which doesn’t allow the current database to be the source database). If the current database is used as the source database, the current record will be skipped when searching for a match – the match must be some other record in the current database.
Keys
The joinonerecord statement has two options for setting up keys, Key and SourceKey. Use the Key option to specify how each record in the current database is identified. For example, suppose the current database is a product list database that contains a field named VendorID, and you want to join that with information from a Vendors database.
joinonerecord "database","Vendors","key","VendorID"
If the Vendors database also has a VendorID field, we’re done. The join will proceed by matching data based on the VendorID field in each database.
If the two databases don’t have an identically named key field, you’ll need to add a SourceKey option to specify how the key is calculated in the source database (in this case, the Key option specifies this for the current database). For example, suppose in the Vendors database the id is kept in a field named ID (instead of VendorID). Adding the SourceKey option will make this work.
joinonerecord "database","Vendors","key","VendorID","sourcekey","ID"
So far these examples have used a single field as the key, but any formula can be used. Suppose the current database is an order tracking database with a Name field that contains full names like Bob Smith and Elizabeth Pride. This database could be joined with a customer list database that uses separate fields for first and last name, like this:
joinonerecord "database","Customer List","key","Name","sourcekey",{First+" "+Last}
As you can see, the source key is actually a formula. This formula must be quoted, which in the example above was done with curly braces ({ and }) so that quotes could be used inside the formula. See Constants to learn about the different ways text can be quoted.
What if the order tracking database also has separate first and last name fields? In that case, the Key option would also be a formula, like this:
joinonerecord "database","Customer List",
"key",{First+" "+Last},
"sourcekey",{First+" "+Last}
The example above creates keys that are case sensitive, so that the name Bill Mazor in the order tracking database would not match BILL MAZOR in the customer list. The formula can be modified so that the keys will match regardless of upper or lower case.
joinonerecord "database","Customer List",
"key",{upper(First+" "+Last)},
"sourcekey",{upper(First+" "+Last)}
If your data might contain accented characters, you could modify the formulas further so that these will be ignored.
joinonerecord "database","Customer List",
"key",{stripdiacriticals(upper(First+" "+Last))},
"sourcekey",{stripdiacriticals(upper(First+" "+Last))}
With this modification, the name Dän will match Dan or Dán when performing the joinonerecord.
Using the Current Field as the Key – If no key option is specified, the current field is assumed to be the key. If both the current database and the Vendors database have a field named VendorID, you can use this field as a key like this.
field "VendorID"
joinonerecord "database","Vendors"
Of course this code will also work, no matter what field is current:
joinonerecord "database","Vendors","key","VendorID"
Joining from the current record in the source database – Sometimes instead of using a key to locate the data to be transferred, you simply want to transfer data from the current record in the source database. To do that, set the JoinFromCurrentRecord option to yes. If this option is enabled, the key and sourcekey options are ignored. This code assumes that a relational template has been set up for the Vendors database.
joinonerecord "Vendors","JoinFromCurrentRecord","yes"
If the template has been set up to specify the data to be transferred (see the next section), the code above will copy the common fields from the current record in the Vendors database into the current database.
Transferring Data
The ultimate goal of the joinonerecord statement is to transfer matching data from the source database into the current record of the current database. But once the matches are found, which fields in the source database will be transferred into which fields in the current record?
If the two databases have fields with matching names, the joinonerecord statement can figure that out and simply transfer all of the fields that match. In that situation, there’s nothing further you need to do, the joinonerecord statement will figure out the fields for you.
If the two databases don’t have matching fields, the joinonerecord statement must include a formula for each field in the current database that will receive matching data. This is done with a parameter specifying the receiving field name (in the current database) enclosed in chevron characters (« and »), followed by a parameter specifying the formula to calculate the data from the source database to be placed in this field. This formula must be quoted.
joinonerecord "database","some database","key",{key formula},
"«field name»",{data formula},
"«field name»",{data formula},
"«field name»",{data formula},
...
Important: Note that the chevrons around the field names are significant, and cannot be omitted. When specifying a destination field name in the join statement, the field name must always be surrounded by chevron characters (« and »), even if the field name doesn’t have any spaces or punctuation. The joinonerecord statement uses the chevron characters to identify which parameters are field names, and which are regular parameters. For example "Key" is a regular parameter, but "«Key»" would indicate a destination field name (in the current database).
Let’s look at a specific example of how joinonerecord works. Suppose the current database is an order tracking database, and you want to join phone numbers from a Customer List source database. However, for this example the two databases use different field names for phone number data: Phone in the order tracking database vs. Telephone in the customer list database. This example shows how to make the join work in this situation.
joinonerecord "database","Customer List",
"key",{First+" "+Last},
"«Phone»",{Telephone}
In the example above the formula is just a field (Telephone), but any formula can be used. Here’s a revised example that uses the formatphone( function to make sure the phone number is formatted using US standard (aaa) nnn-nnnn format as it is transferred into the current database.
joinonerecord "database","Customer List",
"key",{First+" "+Last},
"«Phone»",{formatphone(Telephone)}
Formulas can also be used to split or merge fields as they are transferred. Suppose the current database contains support incidents, with fields for Customer ID and Name. In addition, you also have a separate Customer List database that also has a Customer ID field and has separate fields for first and last names. To join the names from the customer list database into the support incident database, the full name must be assembled with a formula, like this.
joinonerecord "database","Customer List",
"key","CustomerID",
"«Name»",{First+" "+Last}
If you want to use the joinonerecord statement to bring names from the support incident database into the customer list database, two formulas are needed, using the firstword( and lastword( functions, like this:
joinonerecord "database","Support Incidents",
"key","CustomerID",
"«First»",{firstword(Name)},
"«Last»",{lastword(Name)}
If you have additional fields to transfer, include a formula for each field.
joinonerecord "database","Support Incidents",
"key","CustomerID",
"«First»",{firstword(Name)},
"«Last»",{lastword(Name)},
"«Address»",{Address},
"«City»",{City},
"«State»",{State},
"«Zip»",{Zip},
"«Email»",{Email}
In this example, several fields have the same name in both databases, and are simply copied over “as-is”. If you want to transfer all fields with the same names in both databases, but also transfer some fields with formulas, use the MatchingFields option set to Yes. As shown in this example, this option allows you to omit having to explicitly enter a formula for each duplicate field.
joinonerecord "database","Support Incidents",
"key","CustomerID",
"«First»",{firstword(Name)},
"«Last»",{lastword(Name)},
"MatchingFields","YES"
Like the previous example, this joinonerecord will transfer the name, as well as the address, city, state, zip, email, and any other field with a duplicate name.
If you want to transfer most fields with duplicate names, but omit one or two, set up an empty formula for the fields you don’t want to transfer. This example transfers the name, address, city, state and zip, but does not transfer the email address (in other words, the Email field in the current database will not be touched).
join "database","Support Incidents",
"key","CustomerID",
"«First»",{firstword(Name)},
"«Last»",{lastword(Name)},
"MatchingFields","YES",
"«Email»",{}
Note: If omitted, the MatchingFields option defaults to No, but if no field formulas are defined at all, it defaults to Yes.
Note: The order of the joinonerecord statement parameters does not matter. The previous example could be rearranged like this, this code will work the same as the code above.
joinonerecord "MatchingFields","YES",
"key","CustomerID",
"database","Support Incidents",
"«First»",{firstword(Name)},
"«Last»",{lastword(Name)},
"«Email»",{}
Advanced Options
In addition to the primary options described above, you can also specify how joinonerecord handles duplicate keys, control whether or not invisible records are included in the join, and limit the join to a subset of the source database.
No Match
You can customize what the joinonerecord statement does if no match is found. By default, a failed match will cause an error. You can take advantage of this to assign default values to the fields (and possibly perform other functions, perhaps alerting the user).
joinonerecord "database","Support Incidents",
"key","CustomerID",
"«First»",{firstword(Name)},
"«Last»",{lastword(Name)},
"«Address»",{Address},
"«City»",{City},
"«State»",{State},
"«Zip»",{Zip},
"«Email»",{Email}
if error
First="" Last=""
Address=""
City="" State="" Zip=""
Email=""
endif
If you just want to fill in blank values as in this example, you can specify the "NoMatch","empty" option to ask the joinonerecord statement to do this for you.
joinonerecord "database","Support Incidents",
"key","CustomerID",
"nomatch","empty",
"«First»",{firstword(Name)},
"«Last»",{lastword(Name)},
"«Address»",{Address},
"«City»",{City},
"«State»",{State},
"«Zip»",{Zip},
"«Email»",{Email}
You can also specify the "NoMatch","ok" option, in that case joinonerecord will do nothing when there is no match. However, your code can still find out that the match failed by using the info(“found”) function, like this:
joinonerecord "database","Support Incidents",
"key","CustomerID",
"nomatch","ok",
"«First»",{firstword(Name)},
"«Last»",{lastword(Name)},
"«Address»",{Address},
"«City»",{City},
"«State»",{State},
"«Zip»",{Zip},
"«Email»",{Email}
if not info("found")
First="" Last=""
Address=""
City="" State="" Zip=""
Email=""
endif
Finally, you can use "NoMatch","error" to specify that an error occurs if there is no match. This is the default, so leaving this option off has the same result.
Duplicate Keys in the Source Database
The first phase of the joinonerecord operation is to scan the source database and locate a matching record. But what if a key is duplicated? In other words, what if the same key is associated with more than one record in the source database? You can control the behavior of the join in this situation with the DuplicateSourceKey option. The options are to associate the key with the first matching record, the last matching record (this is the default), or to treat this situation as an error.
For example, consider our previous example of updating the current Customer List database with contact information from an “Orders” database (for this example we will suppose that both databases contain fields for first and last name, address, city, state, zip and phone number). Assuming that the Orders database is sorted chronologically, this example will update the current customer’s contact information in the customer list with information from that customers most recent order.
joinonerecord "database","Orders",
"key",{First+" "+Last},
"duplicate source key","last"
Note: Since last is the default option, the final line of this example isn’t really necessary.
Now let’s add a new field to our customer list database. We’ll call this field First Order and make it a Date field. Then we can use the joinonerecord statement to update this field with the date of the current customer’s first order.
joinonerecord "database","Orders",
"key",{First+" "+Last},
"«First Order»",{Date},
"duplicate source key","first"
In an example earlier on this page the joinonerecord statement was used to update phone numbers in an order tracking database from a customer list database, based on the name. But what if there are two records in the customer list with the same name? Which phone number should be copied over? There’s really no way to know, so this should be treated as an error.
joinonerecord "database","Customer List",
"key",{First+" "+Last},
"«Phone»",{Telephone},
"duplicate source key","error"
if error
alertsheet info("error")
return
endif
To learn more about how to handle an error in your code, see Error Handling.
Including Invisible Records in the Join
The joinonerecord statement normally ignores invisible records (records that aren’t selected) - when searching the source database for a match. If you want to include invisible records in the source database when looking for a match, set the JoinSourceInvisible option to Yes. Here is an example that includes all records in the source database in the join, whether the records are currently visible or invisible.
joinonerecord "database","Orders",
"key",{First+" "+Last},
"append","yes",
"join source invisible","yes"
Specifying a Subset
The joinonerecord statement normally includes all visible records when searching for a match. To restrict the search to a subset of the data, use the SourceSubset option. This option is used with a formula that specifies what data to include. This example updates the current record, assumed to be in a customer list database, with phone numbers from the Orders database. However, only orders that occured in the last 90 days will be included, any earlier orders will be ignored by the joinonerecord statement.
joinonerecord "database","Orders",
"key",{First+" "+Last},
"source subset",{Date>today()-90)}
Note: The subset option can be combined with the invisble option if you want to include invisible data in a subset.
Undo Join
Like any other Panorama operation, you can add a startdatabasechange statement at the top of your procedure, like this.
startdatabasechange "currentrecord","Undo Join"
joinonerecord ...
Using Join with a Shared Database
The joinonerecord statement works just fine with shared databases (unlike the join statement). If the database is shared, the joinonerecord statement will lock the record before updating it, just like an assignment does (see lockrecord). If it cannot lock the record (because some other user currently has it locked, the statement will stop with an error.
Since the source database is not modified, no record will be locked. You may, however, wish to synchronize the source database immediately before the join, to make sure that the local copy of the database has the most recent data possible.
See Also
- addrelatedrecord -- adds a new record to the related database corresponding to the current database.
- findrelated -- finds information that matches the current record in a related database.
- Import Database -- importing another database into the current database.
- join -- joins data from another database into the current database.
- Join Databases -- joining another database into the current database (relational join).
- joindialog -- opens the standard Join Database dialog.
- Linking with Another Database -- techniques for relating multiple database files so that they work together.
- posttorelated -- posts data in the current record to the corresponding record in a related database.
- related( -- searches for a record in a related database that matches the current record in the current database based on a relational specification (based on one or more key fields or formulas in each database), then uses a formula to return other information from the same record. This is similar to the lookup( function, but instead of using an individual field for the key, a relation is used (see Relational Database Management).
- relatedarray( -- builds an Text Array by scanning a database and creating an array element for every record that matches a relational specification (based on one or more key fields or formulas). This is similar to the arraybuild( function, but instead of using an individual field for the key, a relation is used (see Relational Database Management).
- relatedrecordid( -- returns the record id of a record in a related database that matches the current record in the current database based on a relational specification.
- Relational Database Management -- linking together multiple databases based on common data.
- Relational Workshop -- tool that assists in composing relational lookup(, superlookup(, lookupall( and arraybuild( functions.
- selectrecordsrelatedto -- selects records in the current database that are related to any record in another database.
- selectrelated -- selects information that matches the current record in a related database.
History
| Version | Status | Notes |
| 10.2 | New | New in this version. |