When working with a text field, the Morph Field Dialog has about two dozen morph operations available for modifying text.
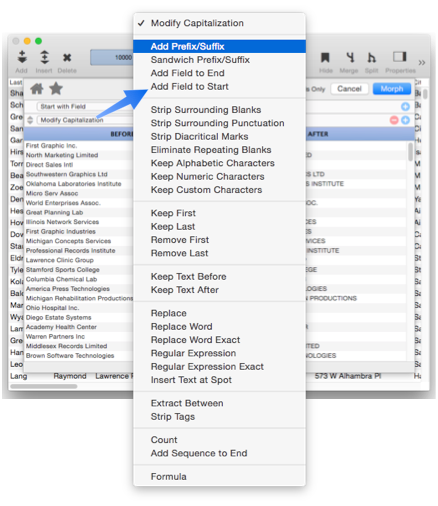
The following sections discuss each of these morph operations.
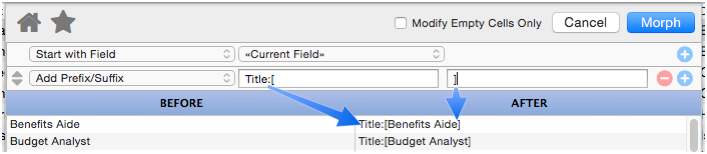
Add Prefix/Suffix
This operation allows you to add a prefix to the beginning of the text, or a suffix on the end, or both (as shown below).
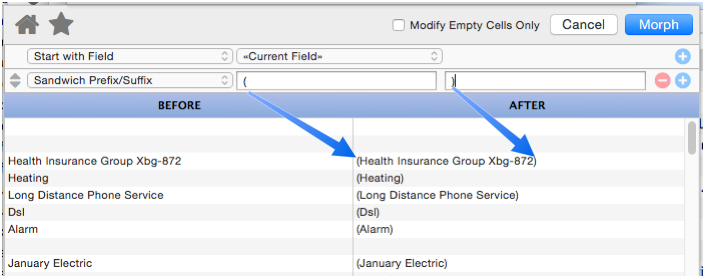
Sandwich Prefix/Suffix
This operation also adds a prefix and/or a suffix. However, unlike the Add Prefix/Suffix option, when the “sandwich” option is used the prefix and/or suffix are only added if the source text is non-blank. In other words, if there is no “meat” then this sandwich doesn’t include any “bread” either.
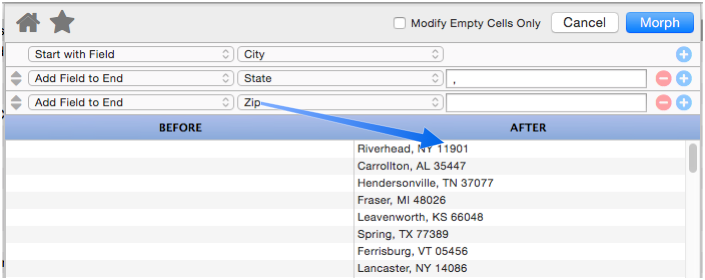
Add Field to End
This operation appends a database field to the end of the manipulated text. It also allows you to specify “connector” text between the existing text and the field being added (in the example below the connector text is a comma and a space).
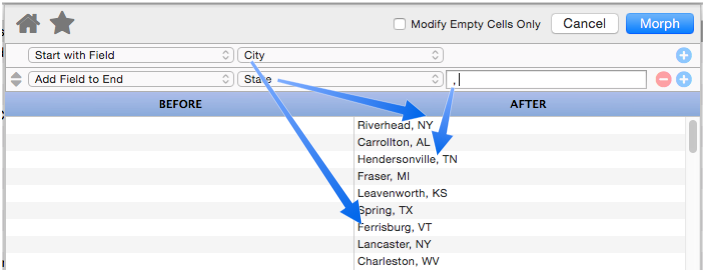
Panorama is smart about adding the connector text – the connector is only added if necessary. In this example if either the city or state is missing for some records, the connector (comma and space) will be omitted.
If necessary, you can append multiple fields, one after the next.
Add Field to Start
This operation is just like Add Field to End, but the field is added at the beginning of the manipulated text.
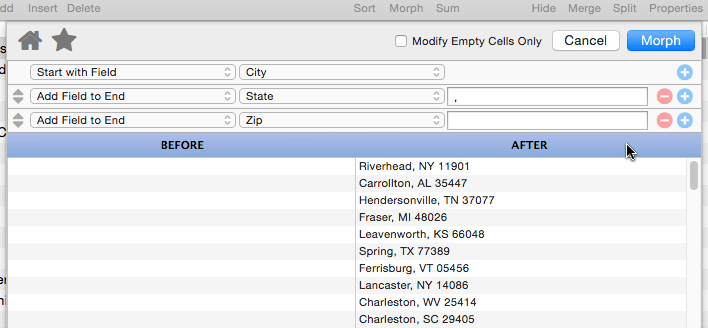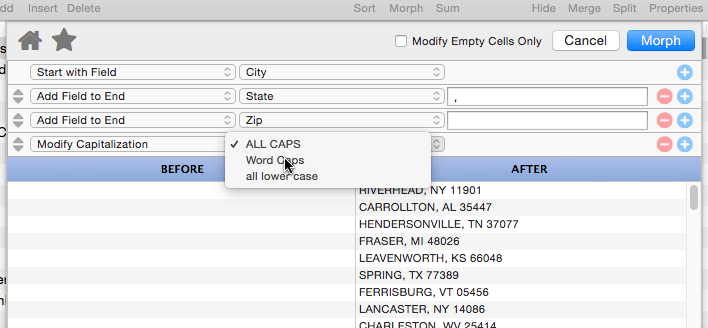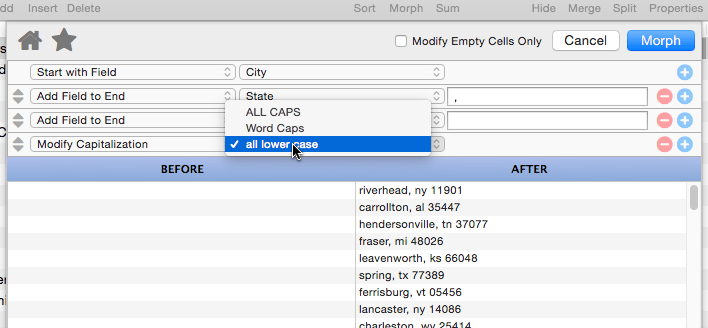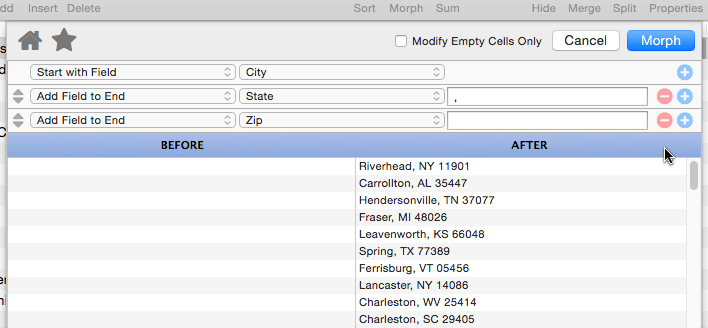
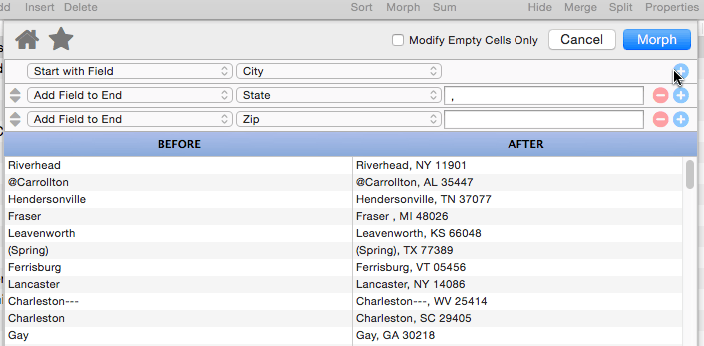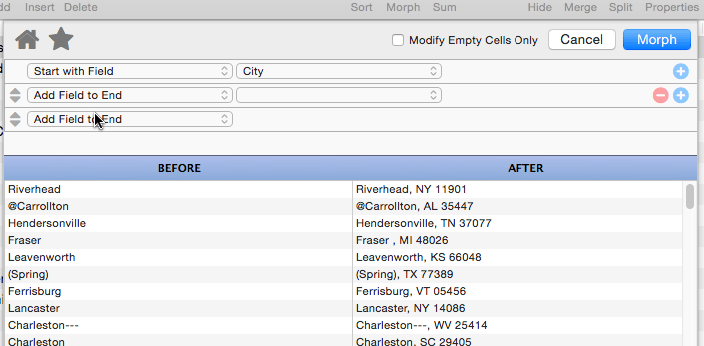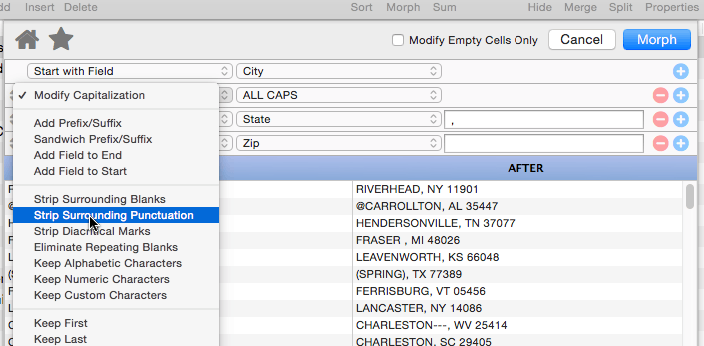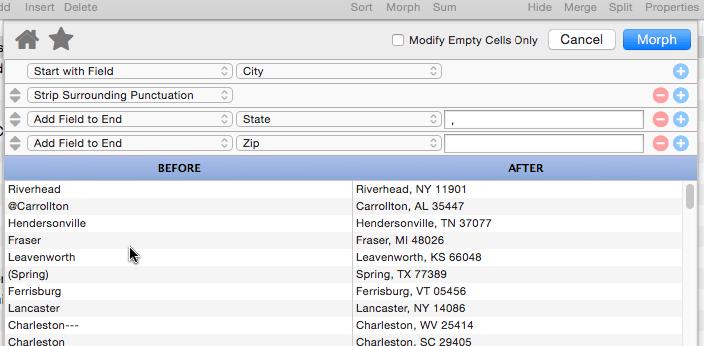
Modify Capitalization
This operation changes the capitalization of the text. Use the pop-up menu to select all upper case, all lower case, or capitalization of the first letter of each word.
Strip Surrounding Blanks
This operation strips off any extra blanks at the beginning or end of the text.
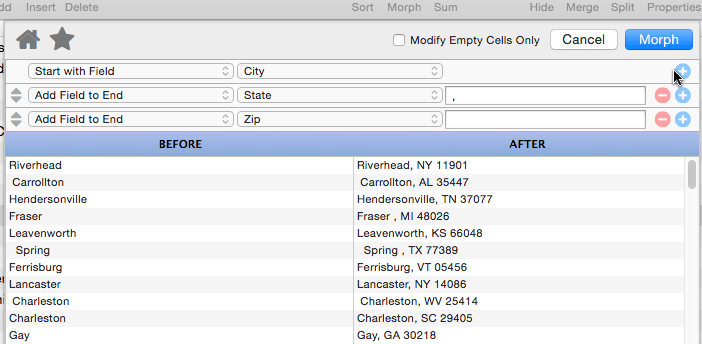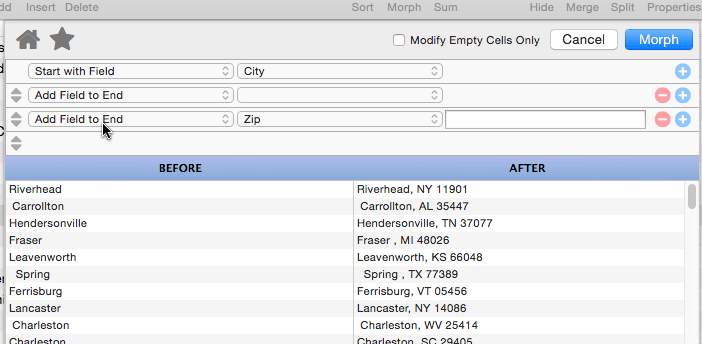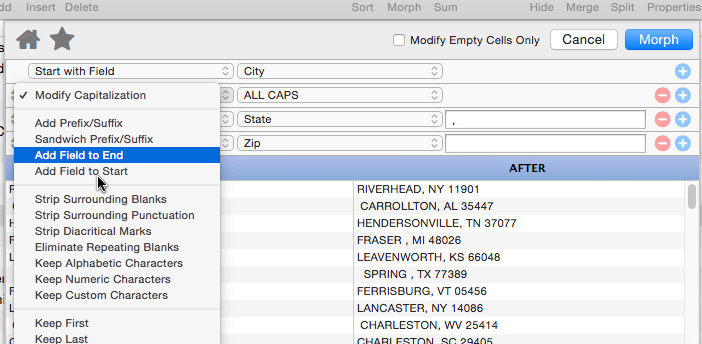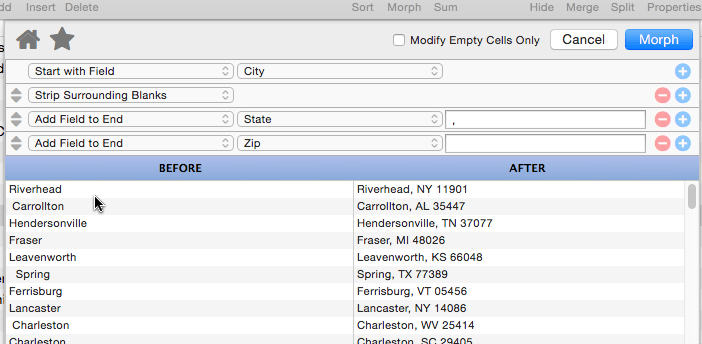
Strip Surrounding Punctuation
This operation strips off any punctuation at the beginning or end of the data. (Punctuation in the middle of the data is left intact.) Punctuation is defined as any non-alphanumeric character, so this can be used to strip off extra parentheses, braces, periods, question marks, spaces etc.
Strip Diacritical Marks
This operation strips off any diacritical marks (accents), leaving only the underlying letter. For example ñ will be converted to n, ü to u, é to e, etc.
Eliminate Repeating Blanks
This operation converts runs of two or more spaces in a row into single spaces. For example
San Francisco
will be converted into
San Francisco`
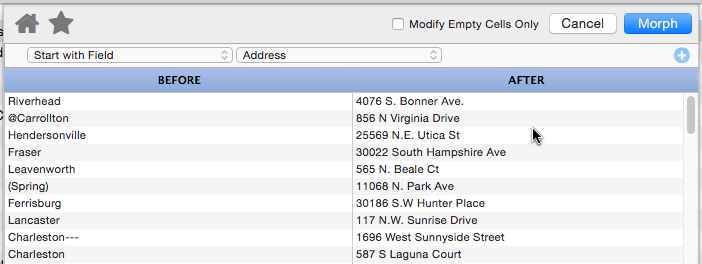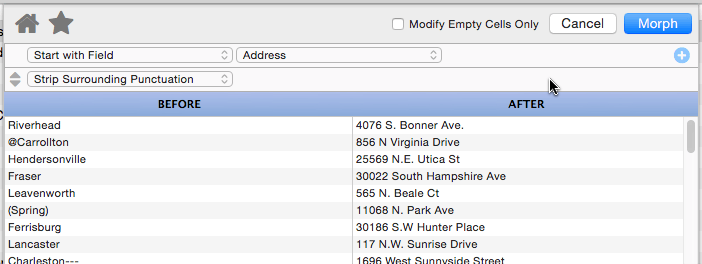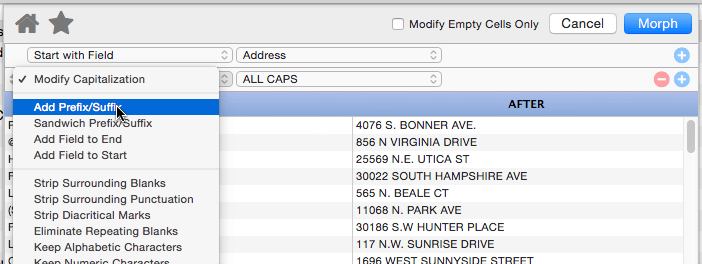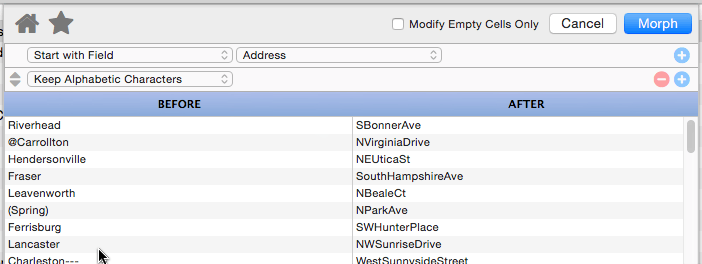
Keep Alphabetic Characters
This operation strips out all non-alphabetic characters. In other words, anything other than A to Z and a to z will be stripped from the text.
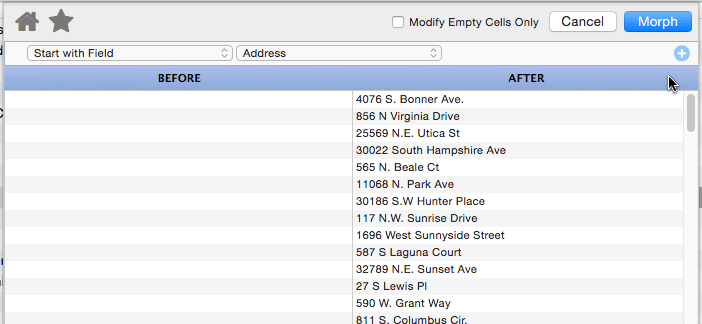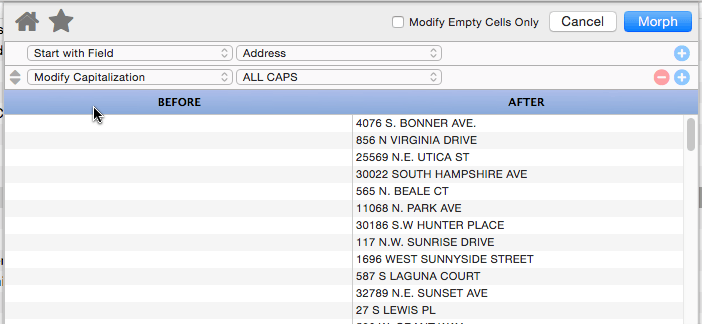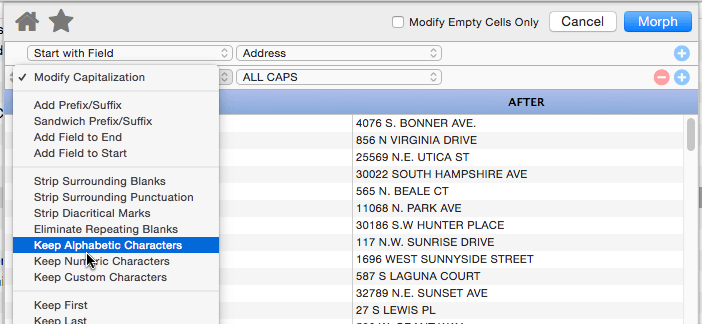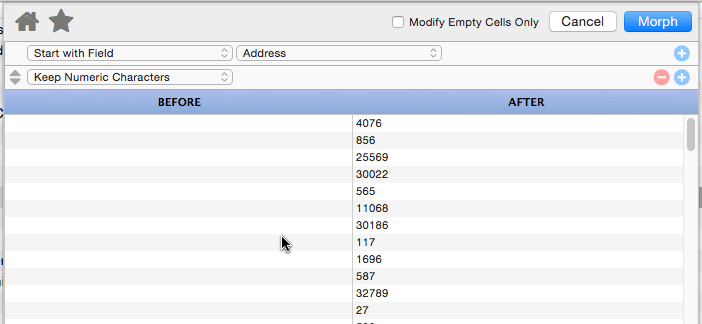
Keep Numeric Characters
This operation strips out all non-numeric characters. In other words, anything other than 0 to 9 will be stripped from the text.
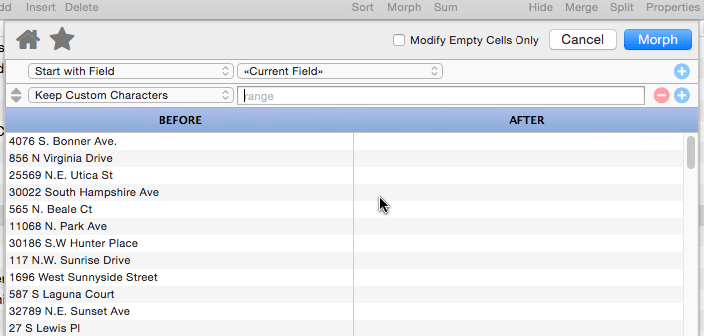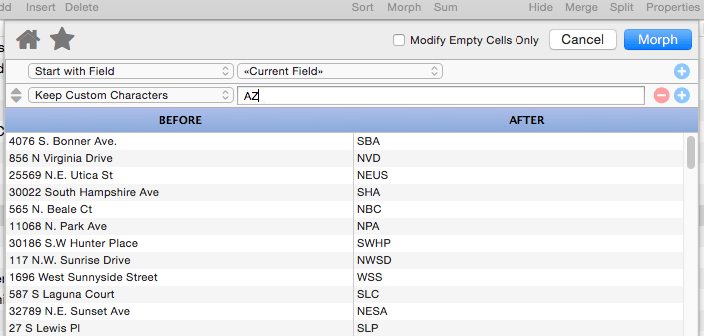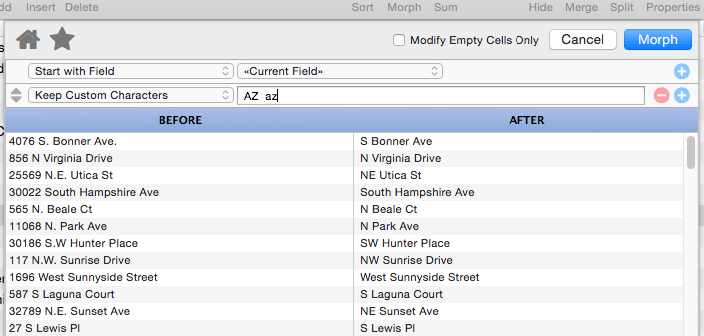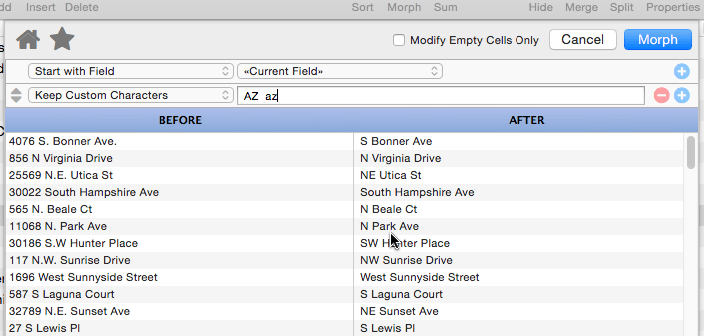
Keep Custom Characters
This operation is more flexible than the previous two, but also a bit more complicated. It allows you to specify exactly what characters to keep and what to strip out. The character to keep are specified as a series of charac- ter pairs. The example below includes three pairs: AZ (A to Z), space-space (space) and az (a to z). The result is that all characters except for letters and spaces are stripped.
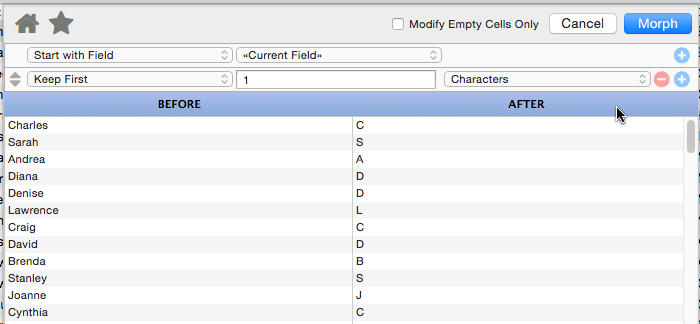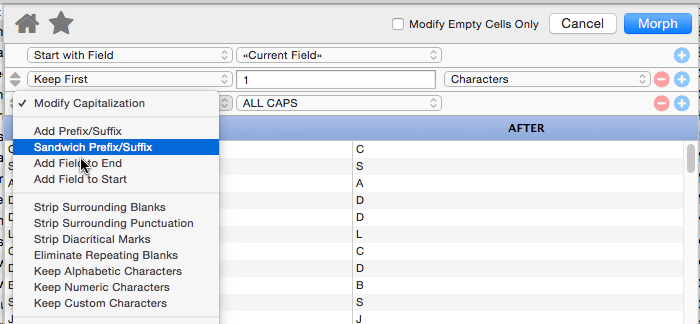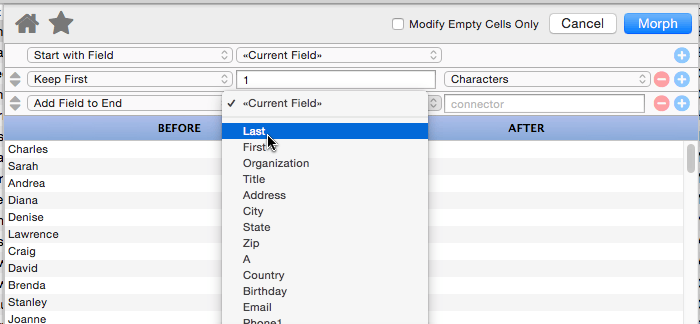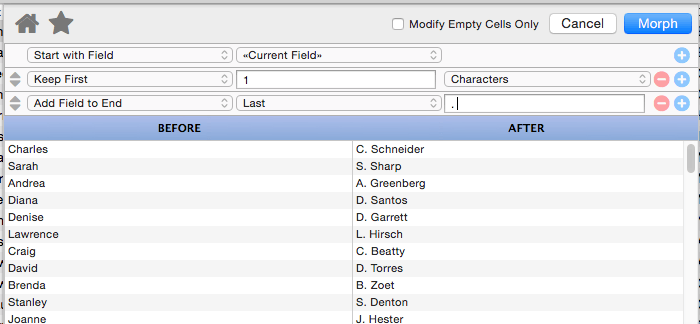
Keep First
This operation keeps the first few letters, words or lines of the data, removing the rest. For example, you could use this to convert a name into an initial.
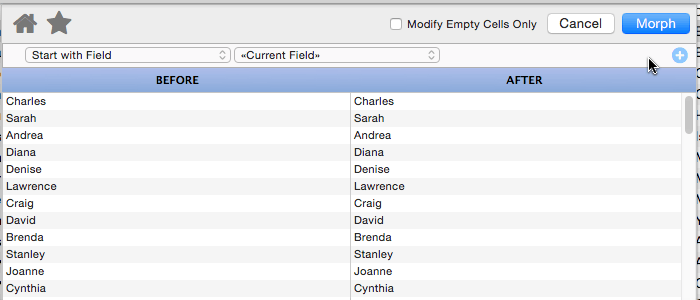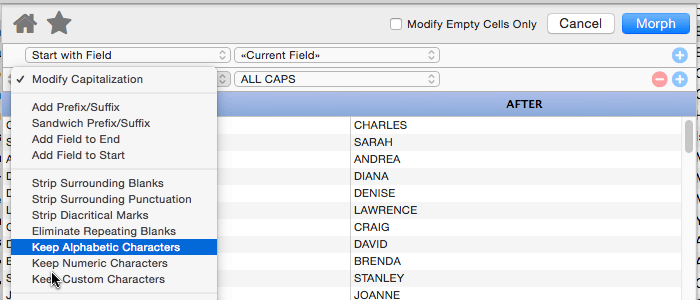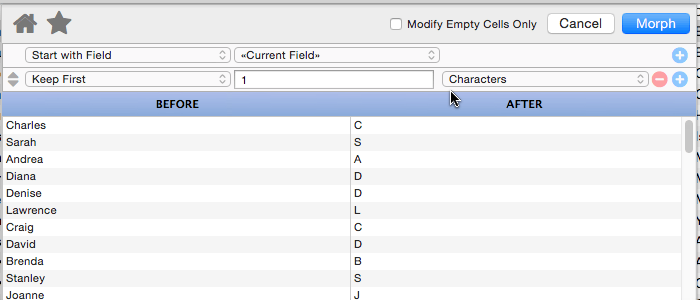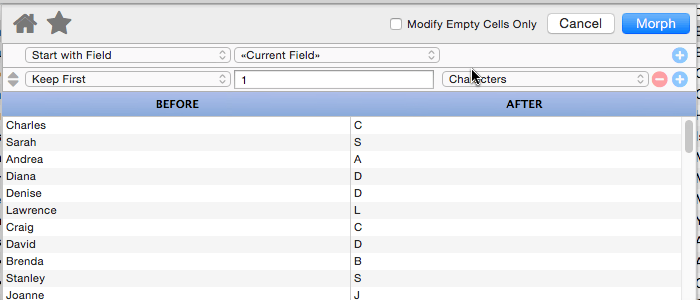
This might not seem that useful, but remember that you can combine multiple manipulations. Here I’ve added a second step that gives us the first initial and last name.
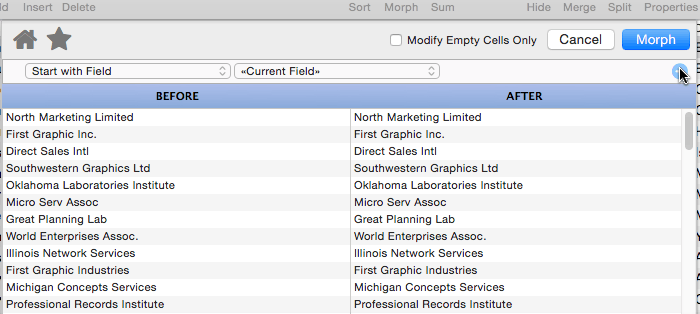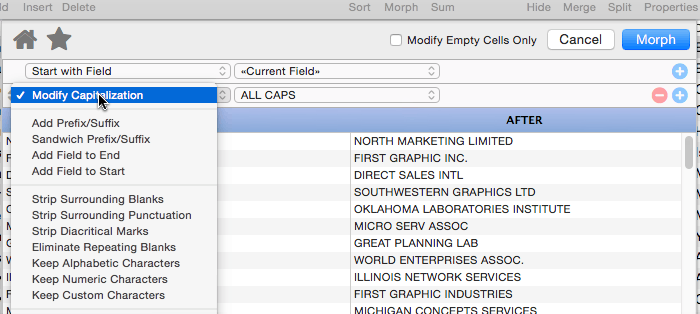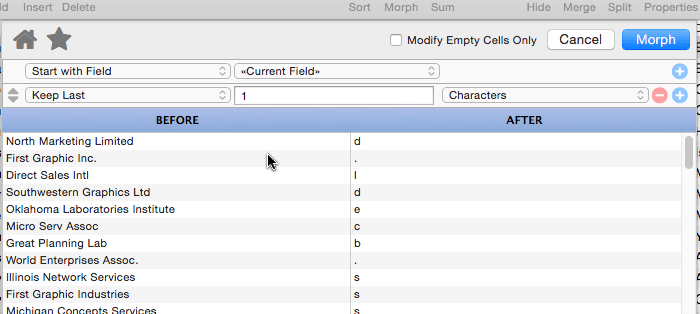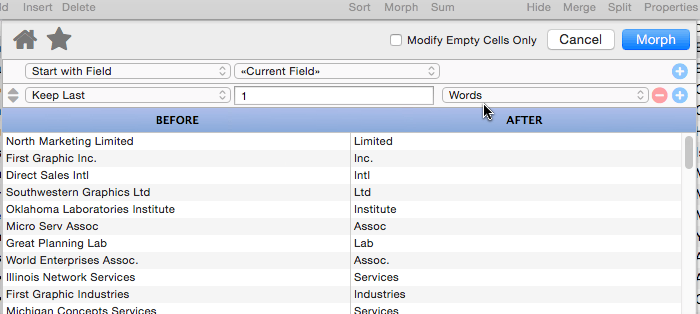
Keep Last
This operation is similar to Keep First, but keeps characters, words or lines at the end of the data. In this example this option has been used to extract the last word from the organization name.
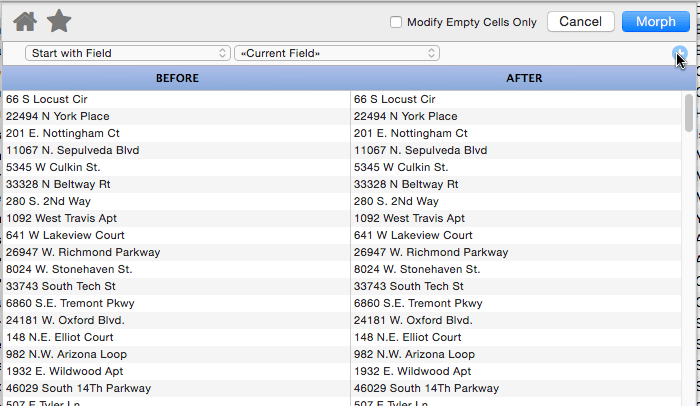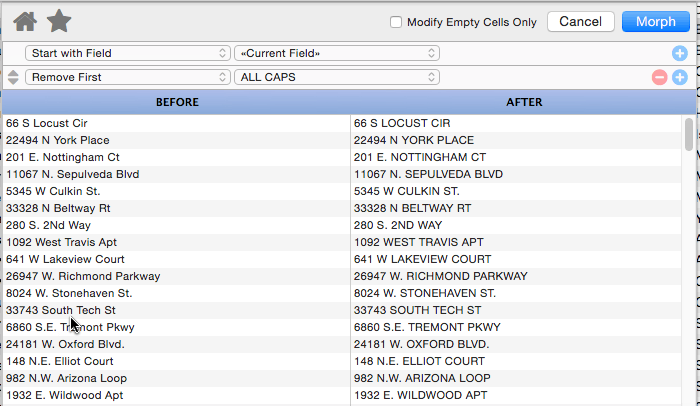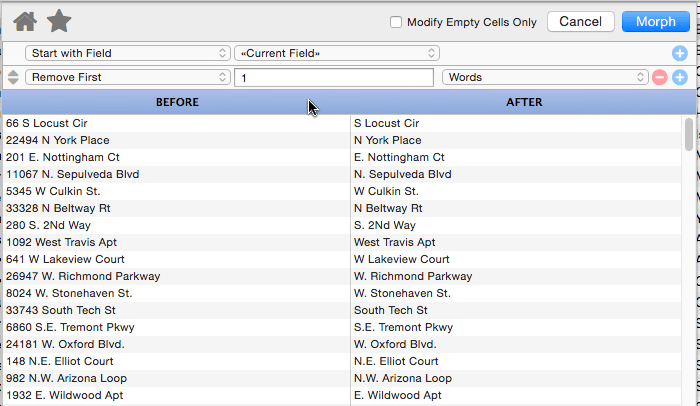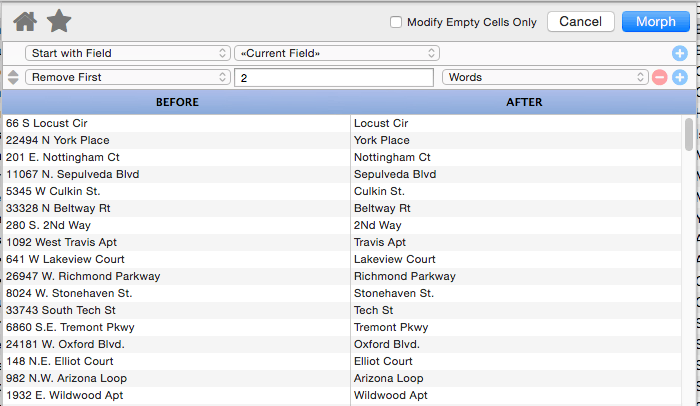
Remove First
This operation removes characters, words or lines from the beginning of the text. In this example the first two words (number and direction) have been removed from the address, leaving only the street name.
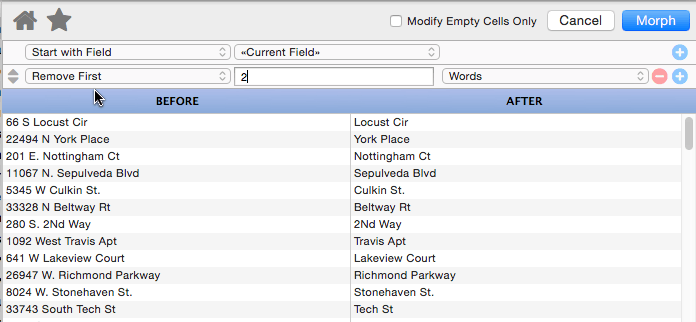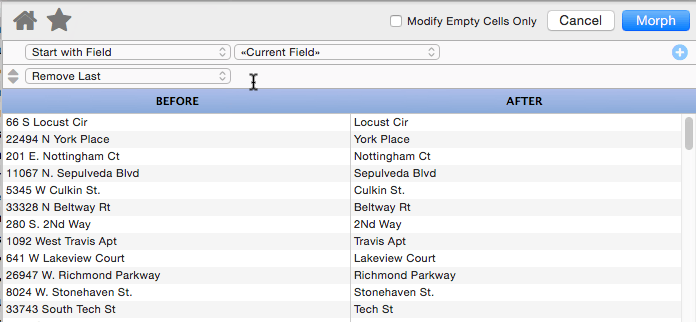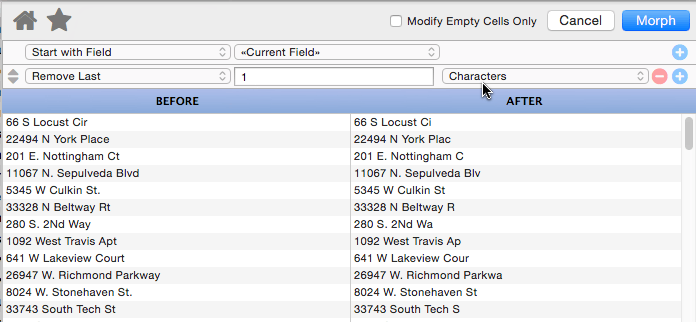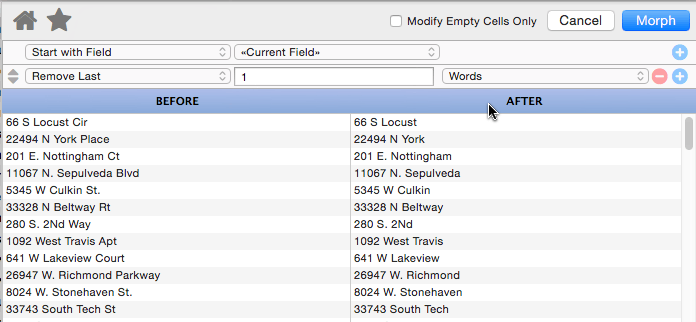
Remove Last
This operation removes characters, words or lines from the end of the text. In this example the last word (Ave, Place, Blvd, St. etc.) has been removed from the address.
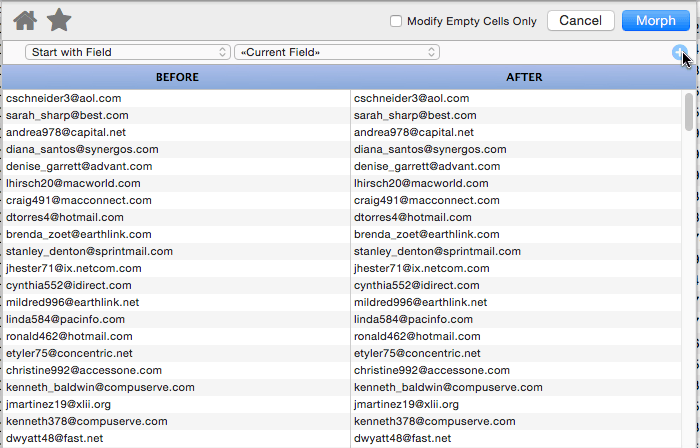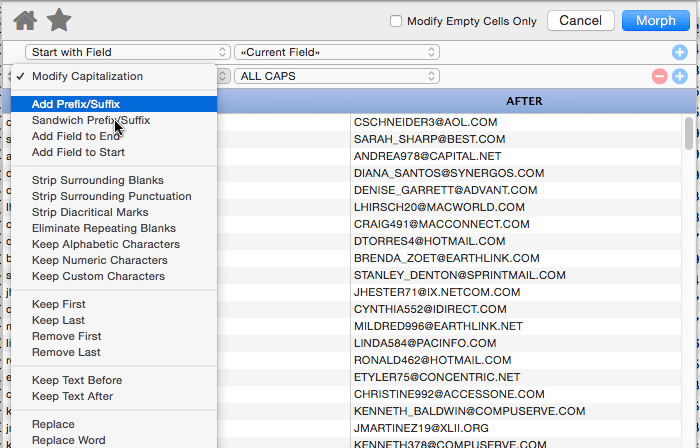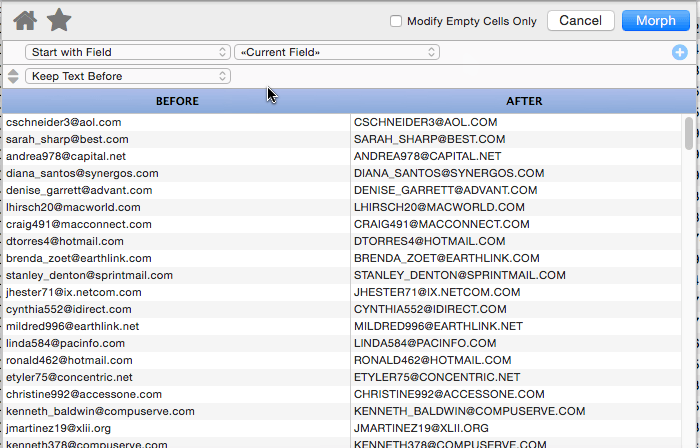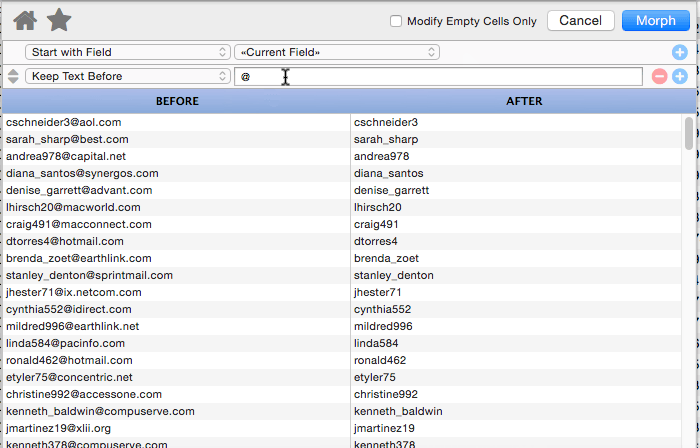
Keep Text Before
This operation keeps the text before the specified matching text, discarding whatever is after. In this example only text before the @ is kept.
Note: The matching text can be more than one character long.
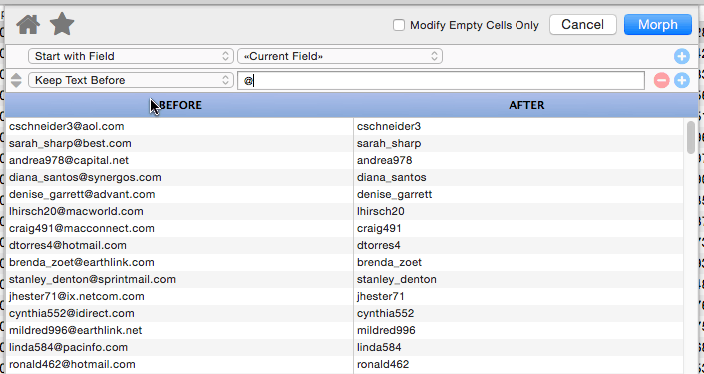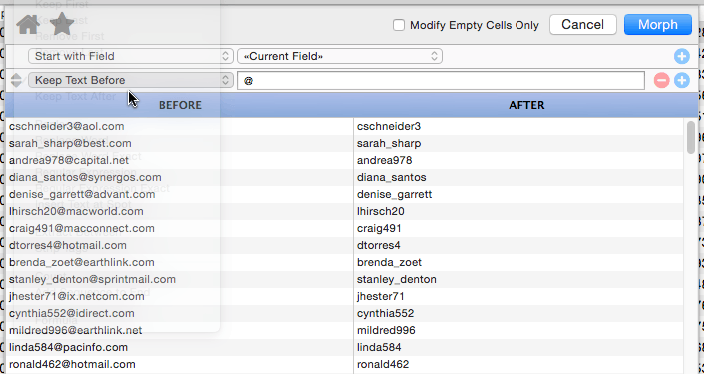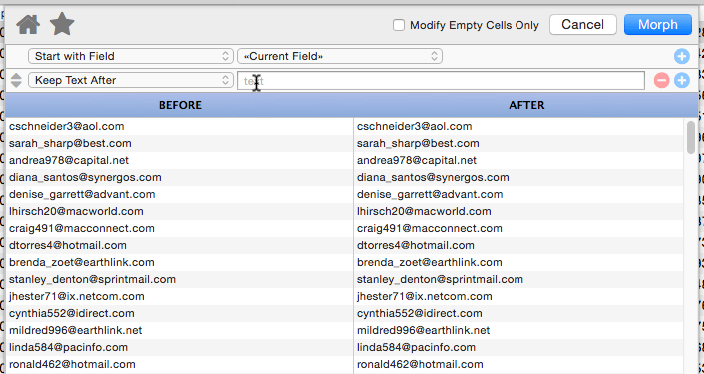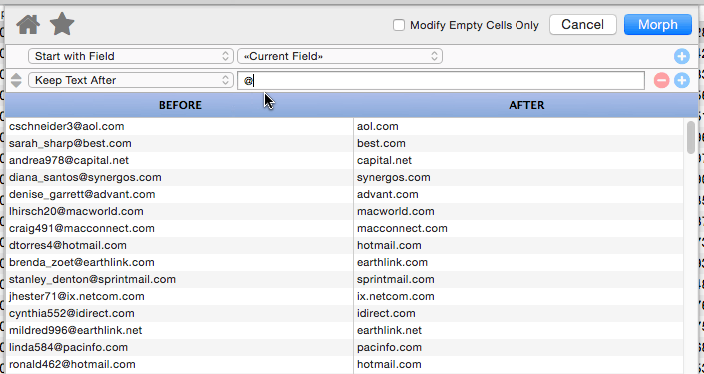
Keep Text After
This operation keeps the text after the specified matching text, discarding whatever is after. In this example we’re keeping the ISP name, while discarding the user name.
Replace
This operation replaces a sequence of characters with another sequence of characters. With this option, you specify the exact text to be replaced (including upper and lower case), and the exact replacement text (also including upper and lower case). Panorama will replace the text even if it is part of a larger word or phrase. For example, if you ask Panorama to exactly replace is with was, it will also change this to thwas, thistle to thwastle and isis to waswas. It will not, however, replace Is, IS, or THIS.
Replace Word
When this operation is used, Panorama will only replace entire words. With this option selected, if you ask Panorama to exactly replace is with was it will not change this to thwas or thistle to thwastle.
When the Replace Word option is used, Panorama is smart about replacing upper and lower case text – it automatically matches the case of the replaced text. For example, if you ask it to replace inc with incorporated, it will automatically adjust the capitalization of the replacement text, as shown here.
inc ☞ incorporated
Inc ☞ Incorporated
INC ☞ INCORPORATED
If the the replacement word has unusual capitalization, for example MacDonald, use the Replace Word Exact option. This disables the automatic capitalization feature.
Replace Word Exact
This operation is similar to Replace Word (see above), but the word is only replaced if it matches exactly, including upper and lower case. There is no automatic capitization, the exact word is replaced with the exact replacment word. For example, if you ask Panorama to exactly replace the word IBM with International Business Machines, it will not replace ibm or Ibm.
Regular Expression
This powerful operation allows you to use a regular expression to specify what text should be replaced (see Regular Expressions). To demonstrate this, consider this database where numbered streets like 7th, 34th, and 127th are incorrectly capitalized. With a regular expression, this can be fixed without messing up street names like Third Street or Thorton Avenue. The regular expression matches one or more numeric digits, followed by Th, followed by a word break (a space or the end of the address). The replacement string includes the numeric digits (thru the use of the $1 capture group) followed by th.
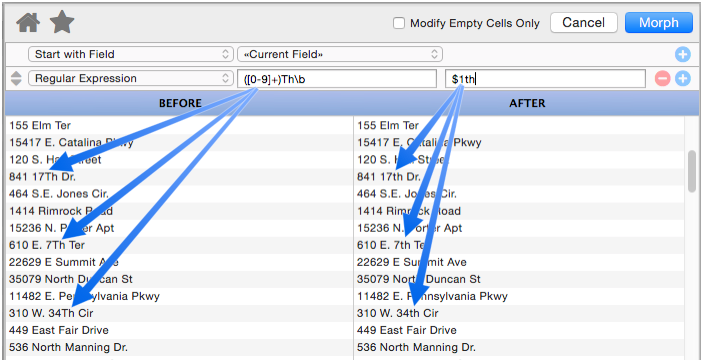
Mastering regular expressions takes some effort, but the payoff can be huge.
Regular Expression Exact
The Regular Expression option described above is not case sensitive. If you need the regular expression to be case sensitive (explicitly matching upper and lower case letters differently), use the Regular Expression Exact operation.
Insert Text at Spot
This operation inserts one or more characters at a specified spot within the text. In this example three insertions are done to add formatting to a phone number field.
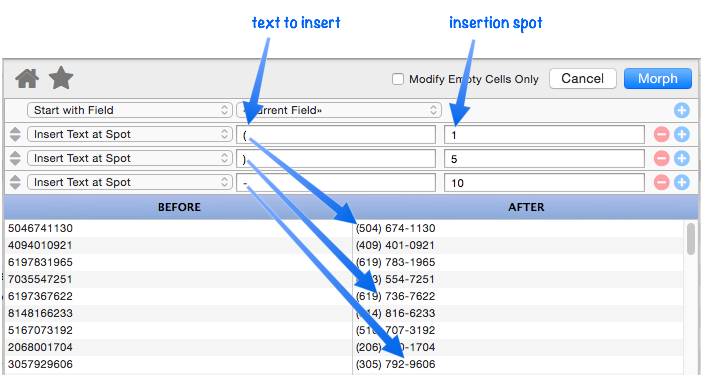
If the insertion spot is a negative number it is relative to the end of the text instead of the beginning.
Extract Between
This option is like a combination of Keep After and Keep Before. It returns text that is after the first matching string and before the second matching string. In this example it is extracting the area code phone numbers.
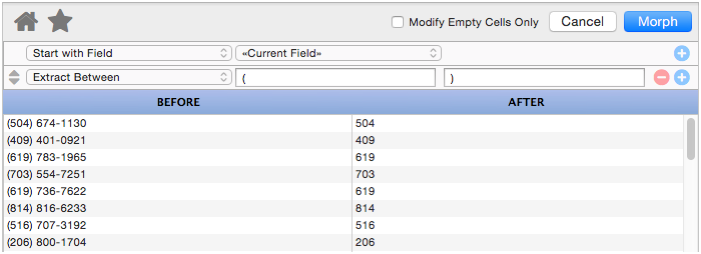
The matching strings can be more than one character, for example this operation could be used to extract text from an HTML tag.
Strip Tags
This option strips out all text that appears between beginning and end tags. If the tags are < and >, this option will strip out all HTML markup from the specified text, leaving just the text itself.
The tags don’t have to be single characters, for example, if the tags are <img and > only image tags will be stripped from the text, leaving all others.
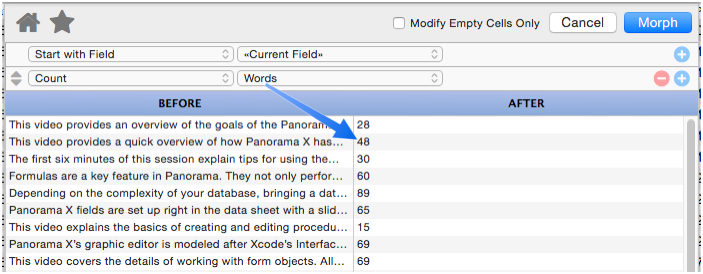
Count
This option counts the number of characters, words or lines in the text. (If you use the lines option, Panorama is actually counting the number of carriage returns in the text.)
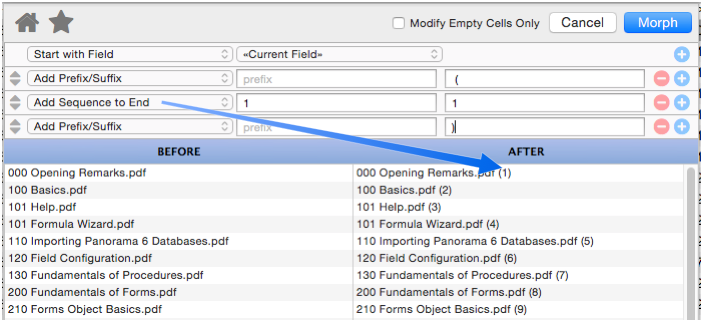
Add Sequence to End
This option adds a numeric sequence to the end of the text. You can specify the starting number and the amount to increase or decrease for each record.
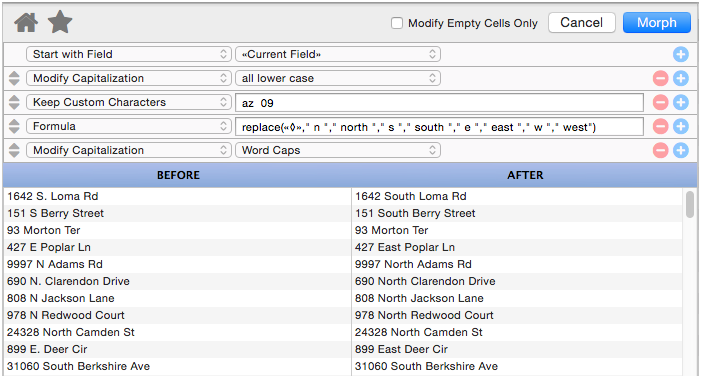
Formula
If none of the options so far will do the job then it’s time to pull out the big gun — a formula. You can use a formula all on its own (see Morph Field Dialog) but you can also use a formula in combination with other manipulations. When used this way, the «◊» symbol will expand into the text produced by the previous manipulations. Then the result of the formula will be fed into any additional manipulations below it. This example expands the abbreviations for North, South, East and West in an address.
The «◊» symbol can be used more than once in the formula. This formula checks to see if the text contains a comma, and if so, swaps it.
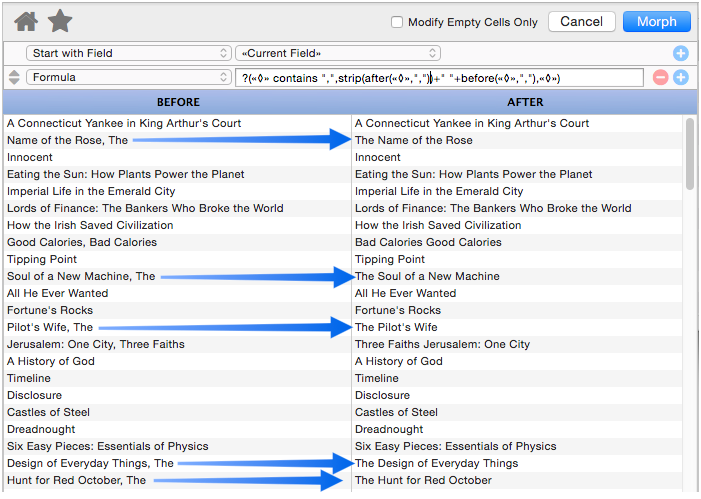
Here is a closer look the formula that peforms the transformation.
?(«◊» contains ",",strip(after(«◊»,","))+" "+before(«◊»,","),«◊»)
See Also
- Duplicate Removal with Unpropagate -- using the unpropate command to remove duplicate data.
- Morph All Fields Dialog -- morphing the contents of the entire database.
- Morph Date Field Operations -- date morphing operations.
- Morph Field Dialog -- morphing the contents of an entire field.
- Morph Field Favorites -- saving and recalling favorite data morphing operations.
- Morph Numeric Field Operations -- numeric data morphing operations.
- morphalldialog -- opens the standard MorphAll dialog.
- morphdialog -- opens the standard Morph dialog.
- Propagate & Unpropagate -- propagating/unpropagating data within a column.
- Shifting Data Left & Right -- sliding data left and right.
- slidedata -- slides the columns at and to the right of the current column.
History
| Version | Status | Notes |
| 10.0 | Updated | Carried over from Panorama 6.0, but with a new operations, including replace word and regular expressions. |